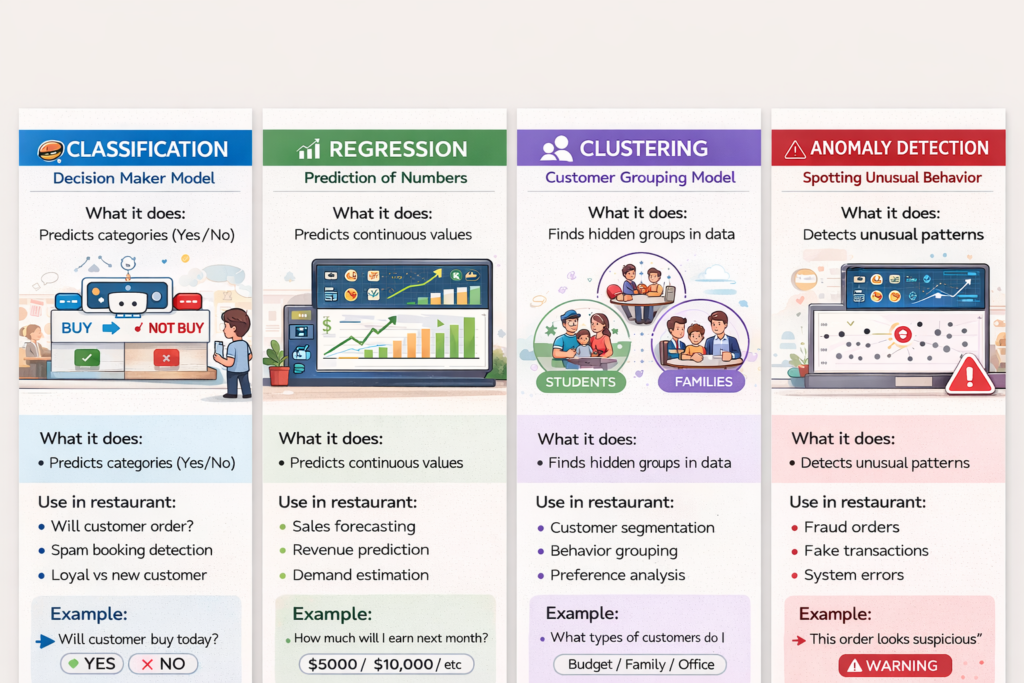
Topics to be covered in this post:
- Classification – decision maker
- Regression – Number prediction
- Clustering – Group Finder
- Anomaly detection – problem spotter
Let’s assume I am the owner of the new start-up restaurant. Everything seems simple and fun at the beginning since there are some clients, a small amount of information, and no complex decisions to make. After a while, my business grows and becomes more complicated because I have to deal with lots of people, unknown data patterns, and uncertain decisions.
A lot of questions arise. What are those clients that will make a purchase? How much money will I gain tomorrow? Why do some clients behave differently from other clients? At times, something goes wrong with the system.
And suddenly I realize that the amount of data will not be enough for me to understand things better, so I have to use a tool that will make it easier for me to analyze it. Such kind of tool could be machine learning models.

Classification model:
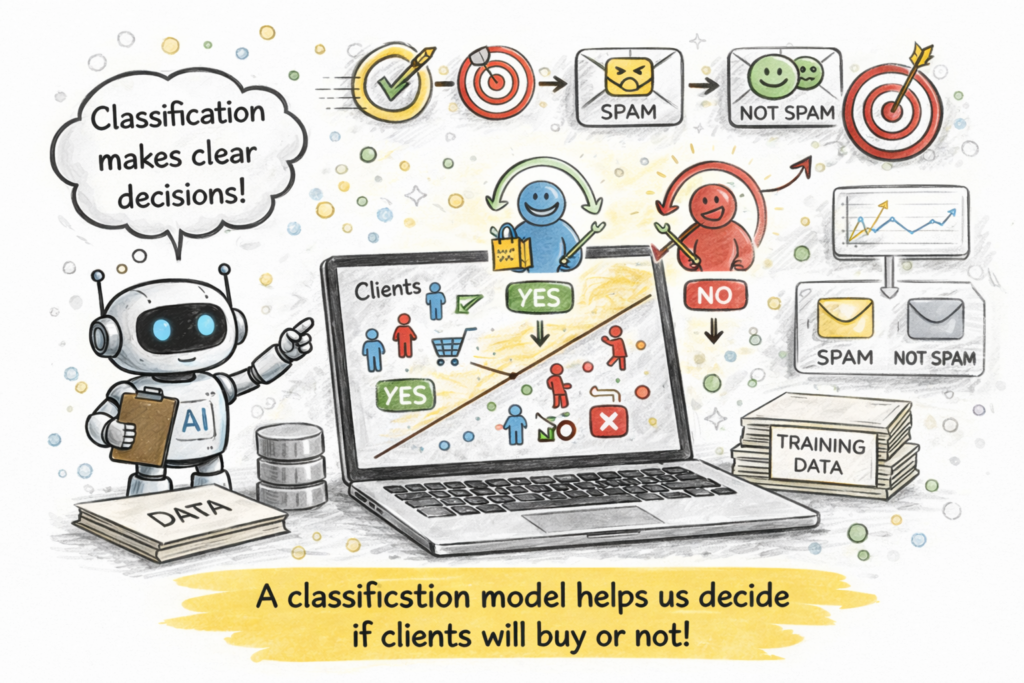
We can see how often the following problem occurs: Which clients will buy a product? The solution to this issue would be to use a classification algorithm because it classifies data by assigning different categories to objects like yes/no, positive/negative, spam/non-spam, etc. If your goal is to make a clear decision, like whether a customer will buy or not, then classification is the best choice. Classification models are trained using labeled data, meaning the system already knows the correct answers during learning.
Regression Model:
With growth in my business, there arises more questions to ask. Apart from asking ‘what,’ there are other questions like how much will you sell in the coming month and how much demand you should expect. This is where we need regression. Regression enables us to predict figures after looking at some patterns in our data. It helps us to make predictions for numbers which will help us get ahead of ourselves. Regression is useful when the output is not a category but a quantity, like revenue, demand, or temperature.

Clustering
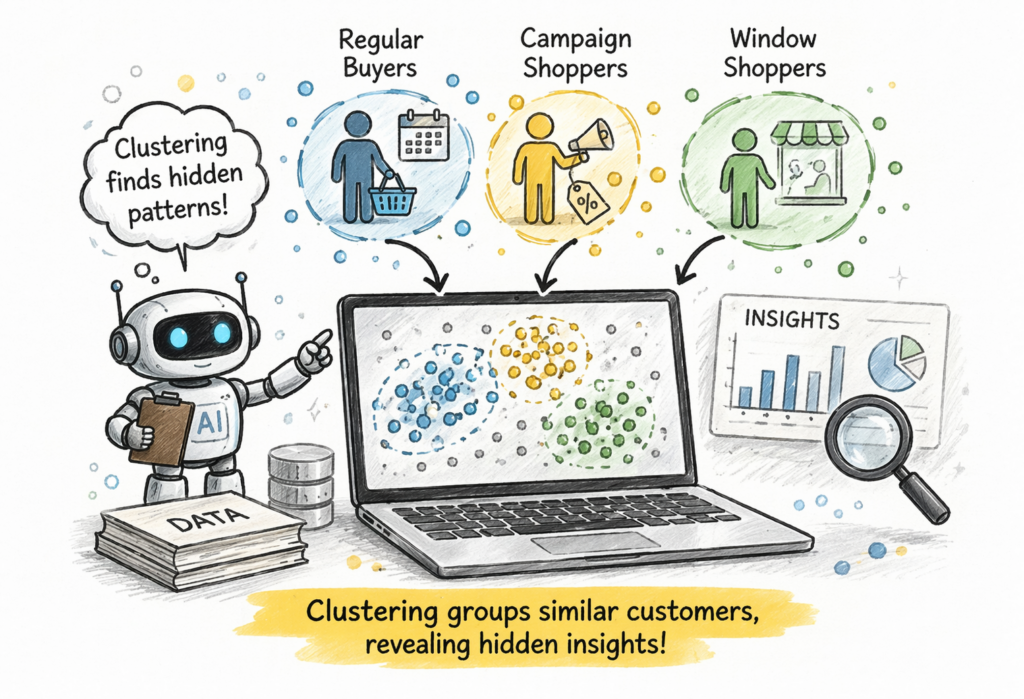
Not all customers behave the same, some customers purchase products regularly, others tend to purchase when there are special campaigns going on, while still others are merely window shoppers. Irrespective of the fact that you may or may not have created groups for these customers, the problem is that they are different. This is where clustering comes in. It groups similar data together, helping you understand hidden patterns without needing labels. Clustering automatically groups similar data points together, making it useful for customer segmentation and behavior analysis
Anomaly detection
And there is the unexpected. On one day, you encounter an activity that seems to be out of place; it’s abnormal. This is the point at which anomaly detection becomes important. Anomaly detection centers on detecting anomalies – it is used to identify problems such as frauds, mistakes or faults before they escalate. Anomaly detection can be particularly effective when used in the detection of frauds, mistakes, or faults. It works by identifying data points that do not match normal behavior. These unusual points are called outliers and often represent important problems.

Summary:
When you look at it closely, all these models are solving different types of problems. Some help you decide, some help you predict, some help you understand patterns, and some help you detect risks. The key is knowing what kind of question you’re trying to answer.
Once you understand your problem, choosing the right model becomes much easier. You stop guessing and start making informed decisions.
In today’s world, this isn’t just useful — it’s essential. From small startups to large companies, everyone relies on data to move forward. And behind that data, there are models quietly working, helping businesses grow smarter every day.
If your goal is to make a clear decision, like whether a customer will buy or not, then classification is the best choice. It’s simple, fast, and works well for yes/no type problems.
If you want to predict numbers, such as future sales or prices, then regression is the most suitable. It helps you estimate values and plan ahead.
If you don’t know the patterns in your data and want to discover groups or behaviors, then clustering is ideal. It helps you understand your data better without predefined labels.
And if your focus is on detecting unusual or suspicious activity, then anomaly detection is the best option. It’s especially useful for identifying fraud or errors.